My dissertation was an investigation on how lexicons perform on sentiment classification of film reviews - this work was later expanded and incorporated into a chapter on the book "Knowledge Discovery Practices and Applications in Data Mining - Trends and New Domains".
A shorter version of this research was presented in Dublin's IT&T 2009 and available here.
The lexicon used here was SentiWordNet. Built from WordNet, SentiWordNet leverages WordNet's semantic relationships like synonyms and antonyms, and term glosses to expand a set of seeded words into a much larger lexicon. It can be tried online here. (also see Esuli and Sebastiani's SentiWordNet paper).
Using SeniWordNet for sentiment classification involves scanning a document for relevant terms and matching available information from the lexicon according to part of speech. There are some interesting NLP challenges involved here: we run the text via a part of speech tagger first to obtain details on whether terms are adjective, verb, etc. Then negation detection is performed to identify parts of text affected by a negating statement (ex: "not good" as opposed to "good"). Then, the document is scored based on terms found and whether it is negated. The overall approach is given below.
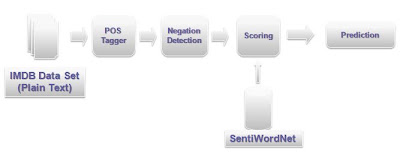
Resources
- Negation Detection - The NegEx algorithm from Chapman et al.
- The NLTK Python library has implementations of various part of speech taggers.
- The Stanford POS Tagger is a Java app implementing the method described here.
I'm in the process of preparing my PhD studies in the area of opninion mining, however i don't have a specific topic in my mind, which area should I focus on.. opninion mining is a big topic..Therefore, Do have any ideas regarding the text mining area for my PhD studies?
ReplyDeleteI'm in the process of preparing my PhD studies in the area of opninion mining, however i don't have a specific topic in my mind, which area should I focus on.. opinion mining is a big topic..Therefore, Do have any ideas regarding the opinion mining area for my PhD studies?
ReplyDeleteIt seems that the page were you could get SentiWordNet has been hacked:( Is there some other way to contact the authors to get it? I would be very grateful for some advice...
ReplyDeleteThe main page for SentiWordNet is here:
ReplyDeletehttp://sentiwordnet.isti.cnr.it/
There is also an online interface to SWN:
http://sentiwordnet.isti.cnr.it/search.php?q=good